SQL Pipeline Syntax in Databricks
Earlier this year, Databricks introduced a new syntax for data querying. It was originally introduced by Google in BigQuery, and now Databricks has adopted it as well. SQL Pipe syntax resembles Microsoft’s KQL, but it is much easier to learn because the syntax has not been reinvented. I like KQL, but I don’t like that I have to look up all the commands from the manual as almost all the functions have been named differently than they have been named in SQL.
One big difference between SQL and the pipe syntax is that SQL is declarative and the order of the operations does not resemble the order what the machine does to return the data you requested. SQL has actually received quite a lot of critique for how unintuitive the order of operations is. SQL Pipes is not procedural language, but the order of the operations is much more intuitive and easier to grasp for beginners.
How to Use it
Let’s say you are a data geek who wants to stay in Stockholm during the Midsummer festival to see the Maypole in Skansen. You decide to look for accommodation on Airbnb but as a data geek, you want to use SQL and Databricks instead of the Airbnb website. You decide to download scraped data from the Inside Airbnb website and crunch the data in Databricks.
Prepare the data using a notebook. First, download the datasets:
%sh
curl https://data.insideairbnb.com/sweden/stockholms-l%C3%A4n/stockholm/2025-03-23/data/listings.csv.gz --output /tmp/listings.csv.gz
curl https://data.insideairbnb.com/sweden/stockholms-l%C3%A4n/stockholm/2025-03-23/data/reviews.csv.gz --output /tmp/reviews.csv.gz
curl https://data.insideairbnb.com/sweden/stockholms-l%C3%A4n/stockholm/2025-03-23/data/calendar.csv.gz --output /tmp/calendar.csv.gz
Then, save it as a table:
%python
listings_df = spark.read.csv("file:///tmp/listings.csv.gz", header=True, inferSchema=True, multiLine=True, escape='"')
listings_df.write.mode("overwrite").saveAsTable("listings")
reviews_df = spark.read.csv("file:///tmp/reviews.csv.gz", header=True, inferSchema=True, multiLine=True, escape='"')
reviews_df.write.mode("overwrite").saveAsTable("reviews")
calendar_df = spark.read.csv("file:///tmp/calendar.csv.gz", header=True, inferSchema=True, multiLine=True, escape='"')
calendar_df.write.mode("overwrite").saveAsTable("calendar")
You want to see the descriptions of available (or partially available) listed apartments for your dated, hosted by a person, that has at least one apartment listed with 50 reviews or more.
One way to do this using the traditional SQL is to use CTEs (Common Table Expression). First, you would have to craft a CTE to find the available listings, another CTE to find hosts having a listing with the required number of reviews, and so on until you have all the steps crafted. Finally, you would have to mesh this all together into the final results. You can do this in a Databricks SQL Query:
WITH listings_with_more_than_50_reviews AS (
SELECT listing_id, COUNT(*) AS review_count
FROM reviews AS r
GROUP BY listing_id
HAVING review_count >= 50
),
hosts_with_listing_that_has_more_than_50_reviews AS (
SELECT host_id, MAX(r.review_count) AS max_review_count_of_hosts_listing
FROM listings_with_more_than_50_reviews AS r
JOIN listings AS l ON r.listing_id = l.id
GROUP BY host_id
),
listings_of_our_qualified_hosts AS (
SELECT id AS listing_id, MAX(h.max_review_count_of_hosts_listing) AS max_review_count_of_hosts_listing
FROM listings
JOIN hosts_with_listing_that_has_more_than_50_reviews AS h ON listings.host_id = h.host_id
GROUP BY id
),
available_listings AS (
SELECT listing_id
FROM calendar
WHERE
(date == '2025-06-20' AND available == 't')
OR (date == '2025-06-21' AND available == 't')
GROUP BY listing_id
),
final_result_table AS (
SELECT l.id AS listing_id, l.host_id, r.max_review_count_of_hosts_listing, l.name, l.description
FROM listings_of_our_qualified_hosts AS r
JOIN available_listings AS f ON r.listing_id = f.listing_id
JOIN listings AS l ON r.listing_id = l.id
ORDER BY r.max_review_count_of_hosts_listing DESC, r.listing_id
)
SELECT *
FROM final_result_table
This is how the query, or the CTE flow, is structured:
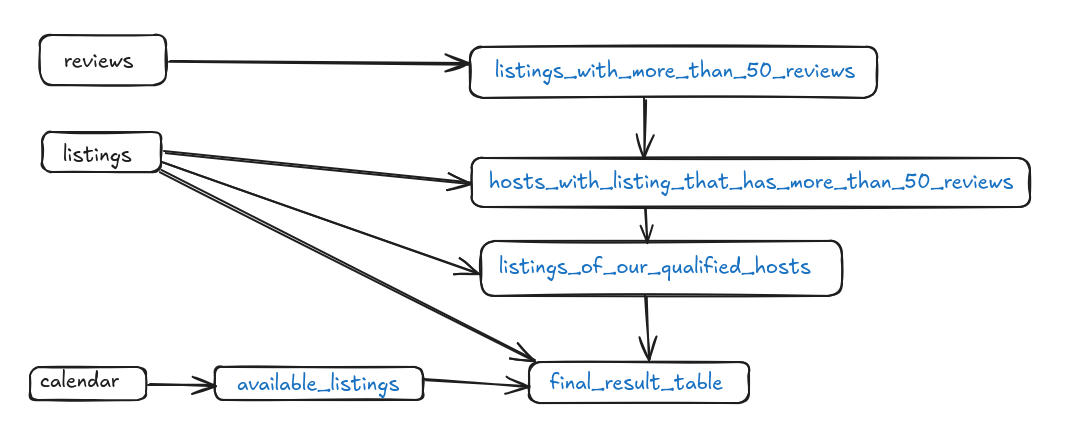
As the image shows, we have two main data flows. One that starts from the reviews and then the listings are joined into it several times. The second flow starts from the calendar and joins into the final results. These two flows are combined in the final_result_table CTE. It is perfectly doable using CTEs but the flow is a bit clumsy. Joining the two flows works perfectly when using CTEs.
How would you do it using SQL Pipe Syntax?
FROM reviews AS r
|> AGGREGATE COUNT(*) AS review_count
GROUP BY listing_id
|> WHERE review_count >= 50
|> AS listings_with_more_than_50_reviews
|> JOIN listings AS l ON listings_with_more_than_50_reviews.listing_id = l.id
|> AGGREGATE MAX(review_count) AS max_review_count_of_hosts_listing
GROUP BY l.host_id
|> AS hosts_with_listing_that_has_more_than_50_reviews
|> JOIN listings AS l2 ON hosts_with_listing_that_has_more_than_50_reviews.host_id = l2.host_id
|> SELECT DISTINCT l2.id, hosts_with_listing_that_has_more_than_50_reviews.max_review_count_of_hosts_listing
|> AS listings_of_our_qualified_hosts
|> JOIN calendar AS c ON listings_of_our_qualified_hosts.id = c.listing_id
|> WHERE (c.date == '2025-06-20' AND c.available == 't')
OR (c.date == '2025-06-21' AND c.available == 't')
|> AGGREGATE MAX(max_review_count_of_hosts_listing) AS max_review_count_of_hosts_listing
GROUP BY c.listing_id
|> AS available_listings
|> JOIN listings AS l3 on available_listings.listing_id = l3.id
|> SELECT available_listings.listing_id, l3.host_id, available_listings.max_review_count_of_hosts_listing, l3.name, l3.description
|> ORDER BY available_listings.max_review_count_of_hosts_listing DESC, available_listings.listing_id
|> AS final_result_table
Look at the difference right from the beginning:
FROM reviews AS r
|> AGGREGATE COUNT(*) AS review_count
GROUP BY listing_id
|> WHERE review_count >= 50
vs
SELECT listing_id, COUNT(*) AS review_count
FROM reviews AS r
GROUP BY listing_id
HAVING review_count >= 50
The SQL Pipeline flow is much closer to how one naturally thinks. The long flow is much clearer and natural using the SQL Pipeline syntax. We can also use multiple WHERE clauses, unlike in the regular SQL. Joining the two dataflows works well here but if that flow were longer, the CTEs might have an advantage as the pipeline syntax does not allow using them. At least not yet.
When and why would you use SQL Pipe syntax?
The Pipe syntax is more intuitive and faster to understand when reading code written by other people. Especially when the code does not combine multiple data flows into one. I’m sure it will be much faster for beginners to grasp but it might take some time for experienced SQL users to adapt.
It also has some small improvements to the SQL syntax, for example multiple WHERE clauses, so no need to do WHERE 1=1 to prevent errors when developing the code. DROP is also a big improvement, as it allows you to specify which columns to remove, instead of cataloging all the needed ones.
I’d expect the pipe syntax to be especially beneficial in cases where the data transformations are long, requiring a lot of filtering but the logic required might not be super complex. Also, the transformations written in SQL Pipe syntax might be easier to create and maintain, even by users who don’t have a lot of experience in SQL.



