In the previous part of the series, we saw how the platforms came to exist. In this part we will see how Microsoft and Databricks describe the platforms themselves, what these platforms contain, and what their architecture is. The goal here is to understand on what aspects the platforms differ and on what aspects they are similar. The big question is, of course, when should I use Fabric and when Databricks is a better choice.
These platforms, especially Fabric, are developing fast, and the things mentioned in this post are likely to become outdated soon.
Let’s first see how the platforms are described by the companies.
High-level overview
| Databricks | Fabric |
|---|---|
| Azure Databricks is a unified, open analytics platform for building, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions at scale. The Databricks Data Intelligence Platform integrates with cloud storage and security in your cloud account, and manages and deploys cloud infrastructure on your behalf. Source |
Microsoft Fabric is an end-to-end analytics and data platform designed for enterprises that require a unified solution. It encompasses data movement, processing, ingestion, transformation, real-time event routing, and report building. Source |
Not that different, right? They emphasize slightly different aspects but both claim to be unified data and analytics plaforms at scale.
Taking a deeper look at the introduction pages and cutting through the zeitgeist AI speak, some differences arise. Databricks emphasizes programmatic access, commitment to open-source, and customers’ options for components such as storage. Fabric emphasizes deep integration of the platform, and ease-of-use.
These differences are noticeable quite soon when you start using the platforms. Databricks requires more set-up than Fabric. Fabric, in turn, does not let you see or change the details of the platform. The administration of the platforms is also quite different, at least at the moment. Databricks is essentially an API-first platform, meaning that you can control everything using APIs, and most features by using the Admin UI. Fabric is the opposite; all control is possible from the Admin UI and only some things are possible to control using APIs.
It’s interesting to see that the design philosophy differences are in some sense similar to Linux/Unix compared to Windows. Linux being open-source and easy to automate through the command prompt while Windows still requires some point-and-click administration, and has a slick and polished UI making everything easy for the beginner.
Features
What about a feature-level comparison? How do the platforms fulfill the normal data platform requirements? Normally, these kinds of tables are done only by corporate buyers, but they actually do serve a purpose for us here. They help us get a high-level picture of what the platforms provide and also serve as a map for us in later parts of the series, when we will start comparing the features in practice.
Data Ingestion, Transform, and Streaming
Data ingestion is the bread and butter feature of a data platform. Getting data into the platform is a fundamental feature of the platform. Data engineers spend a large part of their daily job working with data ingestion.
| Azure Databricks | Microsoft Fabric | |
|---|---|---|
| Data Ingestion | ||
| Orchestrating the pipelines | Workflows / Jobs ¹ | Data Factory |
| Ingesting data | Spark Notebooks | * Data pipelines * Data flows * Fabric (Spark) Notebooks |
| Processing the data | Spark Notebooks | * Fabric (Spark) Notebooks (in Lakehouse, KQL) * Stored Procedures (T-SQL in Warehouse) * KQL Querysets (KQL Database) |
| Streaming | * Spark Structured Streaming * Delta Live Tables |
* Spark Structured Streaming * Event Streams |
| Database mirroring | - | Several² |
¹ Many times combined with Azure Data Factory or a similar orchestration tool.
² Azure SQL, Azure SQL MI (preview), Cosmos DB (preview), Databricks (preview), Snowflake.
It is interesting to see how Fabric has a multitude of options compared to Databricks. Databricks relies on Spark and notebooks for everything, while Fabric offers different options for ingesting and processing the data. Fabric also has an option to mirror the database directly into Fabric, skipping the data pipeline altogether.
Data Storage
What about storage? Ingesting data is important but where will it land?
| Azure Databricks | Microsoft Fabric | |
|---|---|---|
| Data Storage | ||
| Storage Options | Any major cloud vendor storage | * Fabric’s OneLake * Using Shortcuts, major cloud vendor storages |
| Storage Format | Delta Lake (delta tables or any other format) | * Lakehouse, Delta Lake (or any other format) * Warehouse, Delta Lake only * KQL (proprietary) |
Storage is really interesting. At first, it seems that the platforms are the same. They both allow the use of any major cloud provider as the storage. On a closer look, the differences arise.
Databricks is agnostic to storage and it can combine multiple storage accounts or even multiple cloud vendors by using external locations. Using these locations is pretty much transparent when using them from Databtricks.
Fabric is different. On the surface, it forces you to use OneLake, their own storage solution. However, OneLake can have shortcuts to OneLake itself or any major cloud vendor storage. Using these shortcuts is completely transparent. The user does not know whether they are using OneLake or some other cloud storage through a shortcut. OneLake, in effect, can be used to integrate several storages into one. It also exposes a REST API so even 3rd party tools can enjoy this seamless integration. This means that you can use OneLake to combine several cloud vendors’ storages to single virtual storage and use it, for example, from Databricks.
Compute
Compute is the heart of the data platform. It is used constantly and that is why it is so important that it fits to the purpose, scales, and is easy to use.
| Azure Databricks | Microsoft Fabric | |
|---|---|---|
| Compute | ||
| Compute engines | Spark (Photon) | Spark (in Lakehouse) T-SQL (Polaris engine?) (in Warehouse) KQL (Real-time) |
| Compute hosting | Serverless Customer cloud account |
Serverless |
| Transaction support | Table-level | Table-level (Lakehouse) Database-level(Warehouse) |
For the compute engine, Databricks provides only one option: their trusted Spark engine, hosted either in the customer’s cloud account or is serverless, i.e. hosted in Databricks’ account. At the Databricks Data+AI summit in June 2024, Databricks’ CEO Ali Ghodsi said they will focus on serverless compute, providing all the new features first to the serverless compute.
Fabric has several compute engines, but they operate only on serverless compute, i.e. providing less customization options than Databricks. Fabric offers Spark for Lakehouse, Polaris engine (or a modified version of it) for Warehouse, and KQL for the Real Time.
They both provide table-level transactions when using Spark and Delta Lake. Fabric’s warehouse is capable doing database-level transactions.
Data Governance
Data governance is an essential part of a modern data platform. It is an emerging feature, which means that the features are very much in development.
| Azure Databricks | Microsoft Fabric | |
|---|---|---|
| Governance | ||
| Access Control | Unity Catalog (tables / ML-models / …) | Workspace-level |
| Auditing | Unity Catalog | MS Purview |
| Discovery/Catalog | Unity Catalog | MS Purview |
| Lineage | Unity Catalog | MS Purview |
| Monitoring | Unity Catalog | MS Purview |
Databricks has fine-grained and functional access control based on Unity Catalog. It allows managing the access on workspace, catalog, and object level.
Fabric has a different security model. It relies heavily on using workspace as a basic building block for securing the access. Fabric has OneLake security model on the roadmap.
For other features of Governance, Databricks relies on Unity Catalog and Fabric on Purview.
Data governance is one of the areas where platform providers are competing heavily in. This should bring quite dramatic improvements in this area over the next couple of years.
BI / Reporting
Whether data and analytics platform should contain an integrated BI or reporting platform can be debated but it is, of course, nice to have one.
| Azure Databricks | Microsoft Fabric | |
|---|---|---|
| BI / Reporting | ||
| AI/BI ³ | Power BI |
³ Usually combined with an external tool, such as Power BI
Databricks has its AI/BI solution integrated into the platform, but it has been pretty feature light solution. Usually, Power BI or some other BI tool has been used to complement the platform. BI is now one of the Databricks’ investment areas, as we heard from the CEO Ali Ghodsi in the Data+AI Summit this year.
Fabric integrates Power BI into the platform; actually Fabric is Power BI with extended features. Power BI is one the best BI tools on the market.
Automation (CI & CD)
In any production platform, it is important to automate setting up the environment and its maintenance. If operating at scale, it is mandatory. What kind of tools do these platform provide for automation?
| Azure Databricks | Microsoft Fabric | |
|---|---|---|
| Automation | ||
| Automation | * Terraform * Databricks CLI (Preview) * APIs |
* Terraform (Preview) * APIs |
| Git Integration | x | x (preview) |
| CI/CD deployment tool | * Terraform * Databricks Asset Bundles * Git |
* Terraform (preview) * Git |
| APIs | x | x (partial support) |
Databricks has extensive support for automating the platform. It provides several full scale solutions to fully automate setting up and maintain the platform.
Fabric has a number of automation tools available, though many of them are in preview. Some of these features are really interesting. For example using Terraform as the deployment tool seems odd, since it is a third party tool. One would expect Microsoft to use ARM or Bicep for this.
AI / ML
AI and ML features are an integral part of modern analytics platform, and it is the area where platform providers are investing heavily. Platform may offer models, algorithms, and other functionality but it should at least support automation and deployment of the models.
| Azure Databricks | Microsoft Fabric | |
|---|---|---|
| AI/ML | ||
| Tools | MLflow | MLflow |
| AI | Mosaic AI | Prebuilt AI models (preview) |
Both platforms contain MLflow to manage ML models. Both platforms also contain AI features, though Fabric’s are in preview.
Developer tools
For the long term success of the platform, it is essential to provide good tools for the developers. What tools do these platforms offer?
| Azure Databricks | Microsoft Fabric | |
|---|---|---|
| Dev tools | ||
| VS Code extension | x | x (notebooks) |
| Other tools | * PyCharm extension * CLI (preview) * SDK |
Both provide VS Code extension. Databricks has some other tools. In practice, most developers seem to use the web-based UI and notebooks for code developement.
Other features
What other features do the platforms provide?
| Azure Databricks | Microsoft Fabric | |
|---|---|---|
| Other feature | ||
| Data sharing/Collaboration | Delta sharing, Cleanrooms | Fabric external data sharing (only between Fabric workspaces) |
| Operational Databases | - | Fabric Database (preview) |
Databricks has Delta sharing to enable sharing data between organizations. They also have Data Cleanrooms, to process data with another org without actually giving them access.
Fabric has Databases, which was introduced at the Ignite conference, in Autumn 2024. It is still in preview but it is an interesting development for data platforms as Microsoft is bringing operational databases to a data platform for the first time.
Summary of features
On paper, Fabric seems to offer more options than Databricks. For example, for the compute engine, Fabric has three options compared to Databricks’ one. Both platforms tick the boxes pretty well, but as always, the devil is in the details. Many of Fabric’s features are still in preview while writing this. On the other hand, Fabric has some features which Databricks does not have at all. For example, operational databases were introduced to Fabric at the Ignite conference in fall 2024. Databricks does not have anything similar.
Architecture
What about the architecture of the platforms? How are they constructed and how much does a platform’s provider actually share implementation details?
Databricks
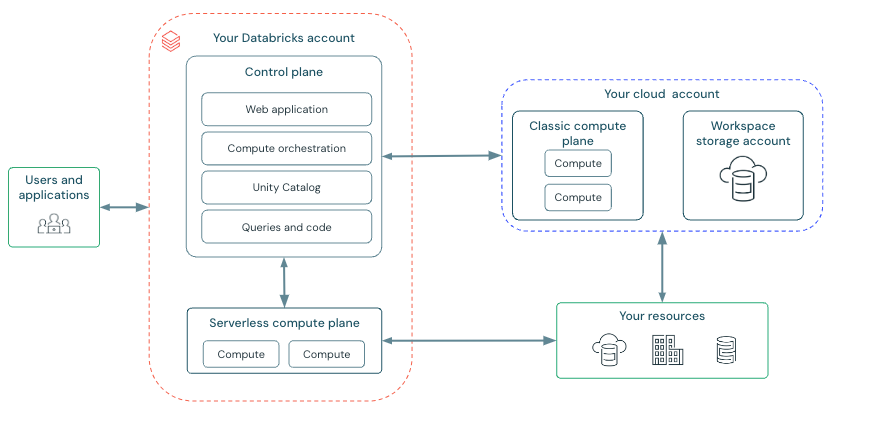
Databricks’ architecture is pretty simple. On a high-level, architecture diagram shown above, there is a control plane and compute plane which are situated in Databrick’s account and in your cloud account. This is a high-level view and it hides a lot of the complexity behind the boxes, like Unity Catalog.
Databricks uses Spark as the compute engine. Spark’s internal architecture is shown below. Basically there is just a cluster manager, driver node and 0-n worker nodes.
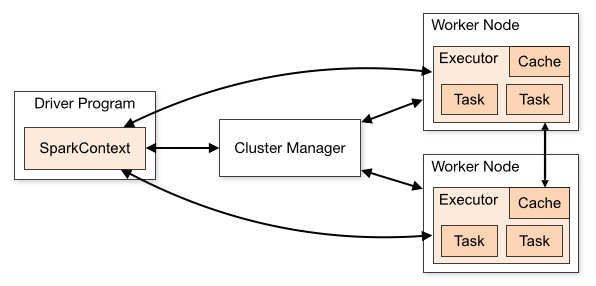
Databricks is basically a managed Spark with some added elements, such as a nice web UI and some additional features such as Unity Catalog, workflows, and Delta Live Tables. Databricks uses Spark basically for all computing, but it needs to be noted that Databricks’ Spark version is not the open-source one but they have proprietary features. They also have a vectorized compute Engine called Photon, which is basically just a Spark engine with lower execution levels written in C++; there is no difference for the user besides the possible speed and cost difference.
That is the compute, but what about the other components: storage and networking? Databricks uses whatever resources you configure it to use; for storage, which typically an object storage, such as ADLS gen2 found from your cloud account. For networking, it uses the network you manage yourself in your cloud account.
Fabric
Fabric provides a wide set of tools for every task. So much so, that sometimes it might be difficult to choose which tool to use. For data ingestion, one can use Data Factory, Data Flows, or Fabric (Spark) Notebooks. Data Factory and Data Flows are low/no-code solutions and notebooks are a pro-code solution.
For data storage, Fabric offers Lakehouse and Warehouse. They both use Fabric’s Onelake object storage as the storage but the feature set they provide are somewhat different. Basically Lakehouse is Spark-based, meaning one can use Pyspark, Scala, R, or SparkSQL notebooks while Warehouse is a T-SQL based solution. Fabric’s Spark is the open-source version.
Reporting and BI in Fabric is done using the excellent Power BI which integrates to Fabric really nicely.
Fabric is basically a blackbox SaaS product for which we don’t have much information on how it is built. In fact, the only source I have come across so far is second-hand information from a recent conference described in Redmond Magazine. I hope this will change in the future, as knowing how the platform is built helps to use it effectively.
Conclusion
This article turned out to be much longer than I expected - and that is a good indication that there is so much to cover on both platforms. The feature list is long and the platforms are huge.
At a high-level, the platforms seem to be similar. Closer inspection reveals there are some differences in the design philosophy and the direction in which the platforms are heading.
The competition at the moment is fierce and the development speed, especially Fabric’s, is exceptional. Both platform providers are investing heavily in development. It is really interesting to see where these platforms will be in the next three years. Fabric is a bit of an underdog, but it is cleverly heading to extend the platform where Databricks has been under-serving the market.
In the next part, we will start by looking how to architecture a simple data platform implementation.



