Why this series?
Another blog series on the differences between Databricks and Microsoft Fabric. Why?
Well, I guess the reasons are purely selfish. I used to be an architect working on a data platform that ran mostly on Databricks. After changing my job, most of the projects I have been working on are Fabric-based so I need to learn Fabric well. The best way to learn something is to write about it. Comparing the new to the old is also valuable for learning. I’ll limit the scope of the series to Microsoft Fabric and Azure Databricks, as those are the platforms I am familiar with.
To understand the platforms, we need to understand how they came into existence. As always, nothing happens in vacuum, but both of the platforms are shaped by the general development of data platforms, cloud technology, and the rise of big data. The history of these platforms is intertwined as Databricks probably wouldn’t exist without the shortcomings of the data platforms of the early 2000s. And on the other hand, Fabric probably wouldn’t exist without Databricks.
Let’s start studying the platforms by looking at a brief history of Databricks.
Databricks
Early Internet and Google’s problem
Google and other Internet giants had a problem at the end of the 1990s. The Internet was becoming too large to be captured, and Internet traffic was generating so much data that they had problems storing it - let alone analyzing or searching it. The traditional method to solve these kinds of problem was to use a database, but they were of no use here. The databases usually had an SMP (Symmetric Multiprocessing) architecture, which meant that they ran on a single machine. If you needed more power, you had to buy a bigger machine. The SMP databases coupled storage and computing meaning that when you ran out of storage space, you were facing a long downtime migrating the data to a larger machine. Big enough machines cost a metric ton of money, if you could find a machine big enough.
There were also database systems that used MPP (Massively Parallel Processing) architecture, such as Teradata. MPP means that the systems didn’t run on a single big machine, but rather a group of machines. These systems were ridiculously priced for startups like Google was back then. A good indication was a poll on Teradata’s homepage in 2003, in which the lowest option for yearly maintenance cost of a single datamart was US$ 1 million (US$ 1.7 million in 2024 dollars). (By the way, when did we stop having polls on corporate websites?)
Google solved the problem. They used commodity hardware, which stored and analysed the data in unison, with many small machines acting like a one big machine. The technology was proprietary, but research ethos was strong in Google’s early days. So they published two research papers, describing the distributed file system (2003) and compute system, called MapReduce (2004).

Early Google servers.
Hadoop
It took a couple of years for outsiders to develop the software systems based on these papers, but in April 2006, it was finally ready and released. It was called Hadoop.
Hadoop was groundbreaking. It was used to run analyses on cheap commodity hardware clusters. A cluster could have had just a couple of machines, or it could have scaled to more than 4,000 computers. For the first time, this scale of computing was available for universities and startups, that could not afford proprietary cluster computing. Hadoop gave results to problems and questions that couldn’t be answered before.

Even though Hadoop was great, it was not perfect. It had to be programmed using a model called MapReduce, which was a beast to program. Hadoop programs usually required many phases or tasks, and each of them required the data to be written on a disk, which was a time-consuming operation. Hadoop also consisted of a large number of software packages, each of which had its own release cycle. You had to have compatible versions of all the components for the system to work correctly, so upgrading a cluster was difficult, as it was later discussed in an episode of Software Engineering Daily podcast.
Enter the Spark
Matei Zaharia was born in Romania, and later moved to Canada before finally settling in the US. He was considered a wunderkind of data science, especially on distributed systems. He won several prizes and competitions in science and programming before he finally entered UC Berkeley. As a PhD student in Berkeley’s AMP Lab (Algorithms, Machines, and People) and an intern at Facebook, he saw firsthand the problems users had with Hadoop. He wanted to help them, as he mentioned on Reddit.
Reynold Xin, one of the AMP Lab students and Databricks co-founders, later said in a conference talk that Zaharia created Spark to help another student to participate in the legendary Netflix Prize competition. According to Xin, Spark was used in the competition to place second, losing the US$ 1 million prize money by 20 minutes.
Whatever the real origin was, Zaharia’s solution was to create a general-purpose distributed compute engine called Spark. Spark was easier to use than Hadoop and significantly faster. Zaharia started working on it in 2009, and it was open-sourced in 2010. In just a couple of years, Spark really took off. Over the years, it became the de facto standard of distributed analytics.
Why did Spark take off like a rocket? If the early adopters of Hadoop were startups, universities, and other shoe-string budget organizations, why legitimate companies started to move to Spark. Zaharia tells his point of view in his book about Spark.
According to him, single processor core speed development started to plateau around 2005, which caused processor manufacturers to start increasing the number of cores. This in turn led to the need for parallel programming models, such as Spark. In addition, the cost of collecting data continued to decline.
The end result is a world in which collecting data is extremely inexpensive—many organizations today even consider it negligent not to log data of possible relevance to the business—but processing it requires large, parallel computations, often on clusters of machines. Moreover, in this new world, the software developed in the past 50 years cannot automatically scale up, and neither can the traditional programming models for data processing applications, creating the need for new programming models. It is this world that Apache Spark was built for.
To the Cloud: Databricks
Spark was a fine piece of software, but it required a lot of manual work to set up and maintain the clusters. With on-premise infra, this wasn’t exactly easy. In 2013, Databricks, the company, was founded to provide cloud-based Spark platform and commercial support for users. It was founded by Zaharia and other members of the AMP Lab research team.

 Databricks’ first investment deck 2013
Databricks’ first investment deck 2013
Zaharia and Databricks continued to invent more products, making them available through Databricks and also open-sourcing them. These products included MLlib, Structured Streaming, Delta, and MLflow.
 In 2017, only four years after its inception, Databricks believed it will dominate the analytics world. Slide from Databricks’ investment deck in 2017.
In 2017, only four years after its inception, Databricks believed it will dominate the analytics world. Slide from Databricks’ investment deck in 2017.
Originally, Spark wasn’t a database system. Instead, it operated on bare files exposed by the cloud storage. This caused problems when updating the files or with streaming data. The reader of the file didn’t know if the data in the file was still being updated. You couldn’t enforce the structure of the data. With the introduction of Delta in 2017, Databricks and Spark started to include database-like features, such as transactions. Later, they brought it even closer to a regular data warehouse by introducing the Delta Lakehouse and Unity Catalog.
Databricks continued to invent and grow. By 2024, its valuation was rumoured to be 55 billion dollars. In just a few years, it had become the juggernaut it had envisioned.
 Spark summit 2013, 500 participants
Spark summit 2013, 500 participants
 Databricks Data+AI summit 2024 (renamed from Spark Summit). 17,000 participants.
Databricks Data+AI summit 2024 (renamed from Spark Summit). 17,000 participants.
Databricks has a special relationship with Microsoft. In 2017, Databricks and Microsoft announced a co-operation. Microsoft would provide Databricks as a first-party service in Azure. It is even called Azure Databricks. Microsoft would allow Databricks to integrate to Azure’s components, such as storage, as it was Microsoft’s own service. For years, their partnership existed peacefully, until at the Build Conference 2023, out of the blue, Microsoft announced its new data platform. It was called Fabric.
Microsoft Fabric
Microsoft Fabric is not a single product but a combination of about a dozen Microsoft products, so it doesn’t have as clear-cut history as Databricks. One thing is sure, though: Fabric wouldn’t exist, at least not in this form, without Satya Nadella.
Nadella’s problem
When starting as the CEO of Microsoft on February 4th, 2012, Satya Nadella faced a challenge. As he describes in his book “Hit Refresh,” he inherited a company with a strong culture of viewing open-source software as its enemy. For Nadella, the need for transition was clear. The transition to the cloud made him realize that Microsoft was not just a technology provider but also operated the tech in cloud, and clients wanted to run other products besides just the Microsoft stack.
 Nadella was appointed as Microsoft’s third CEO in 2014. By Briansmale, CC BY-SA 4.0
Nadella was appointed as Microsoft’s third CEO in 2014. By Briansmale, CC BY-SA 4.0
Microsoft embraces open-source
Microsoft had been flirting with the cloud since 2005, but soon after Nadella was appointed as the CEO of the company, the change started picking up pace. Developers were aghast to see Microsoft supporting open-source software in their offerings. The announcement of Spark for HD Insight in 2015, as well as the acquisition of the Revolution Analytics meant that the R language was integrated into multiple products. In 2016, Microsoft announced its commitment to Spark.
I remember talking to Microsoft engineers during those years, and they seemed just as surprised as we outsiders were. They were also really pleased to see that their company was embracing the best solutions on the market instead of trying to make everything in-house.
Converging the tools
Until 2019, Microsoft’s products were separate and lacked a proper data platform. But then came Azure Synapse Analytics. Synapse’s selling points were: “End-to-end analytics solution”, “Platform out-of-the-box”, “Integrated components”, “Eliminates the divide between datalake and data warehouse”, and “All capabilities in single place”. As we later saw, this was pretty much the same sales talk as that used for Fabric. So what went wrong the first time?
Initially, there was a lot of interest in the market for Microsoft’s unified data platform, but apparently the development speed and the features of the platform just couldn’t compete head to head with other big platforms, like Databricks and Snowflake.
From a personal experience, I saw one large scale data platform project which was using Synapse Analytics. It was abandoned after a couple of years when it became clear that the platform was not mature enough and the development speed was just too slow. Later the project was implemented on Databricks. In last couple of years Synapse just couldn’t compete with the big data platform providers. I’ve heard about several data platform projects where Synapse was quickly dismissed after initial research. Microsoft read the market and saw Databricks, Snowflake and all the other data platforms passing them from left, right and center, and saw that they needed to do better.
Enter the Fabric
At the Build conference in 2023, Microsoft announced their new data platform, Fabric. According to Satya Nadella, it was their biggest data product launch since SQL Server. Fabric wasn’t created from scratch but it’s a combination of at least three major lines of software. Azure Synapse Analytics, Power BI, and Purview. A big part of Fabric are also the open-sourced innovations which are made by Databricks, such as Delta Lake and MLFlow.
Was Fabric just a rebranding of Synapse Analytics or was it really a new platform?
There are definitely lots of old parts that have been reused but there is at least one major difference: the wiring of the components to work as a seamless platform. The latest additions, such as Fabric Databases, which bring operational databases to an analytical platform, are also a major differentiators. In my view, it is not just a marketing gimmick but Fabric truly is a new data platform.
 Fabric is an amalgamation of a number of products. Source
Fabric is an amalgamation of a number of products. Source
Conclusions
The modern data platform has to thank the early Internet search providers, Google and Yahoo. They started the development which lead to Hadoop, Spark, and eventually the Lakehouse paradigm. It also required companies to willingly publish release papers and release software as an open-source. One could think that the modern data warehouse is a triumph of openness and sharing.
Being open, of course, was not enough. It also required failure of the traditional data warehousing. As the Internet and falling costs of data storage drove the data amounts organizations gather to be on a constant rise, traditional data warehousing just could not keep up.
Databricks started from a single product and has evolved into a platform but it is still largely based on a single product: Spark. How well Databricks has been able to ride the data and AI wave from a research group to a start-up to a juggernaut of a company, is remarkable.
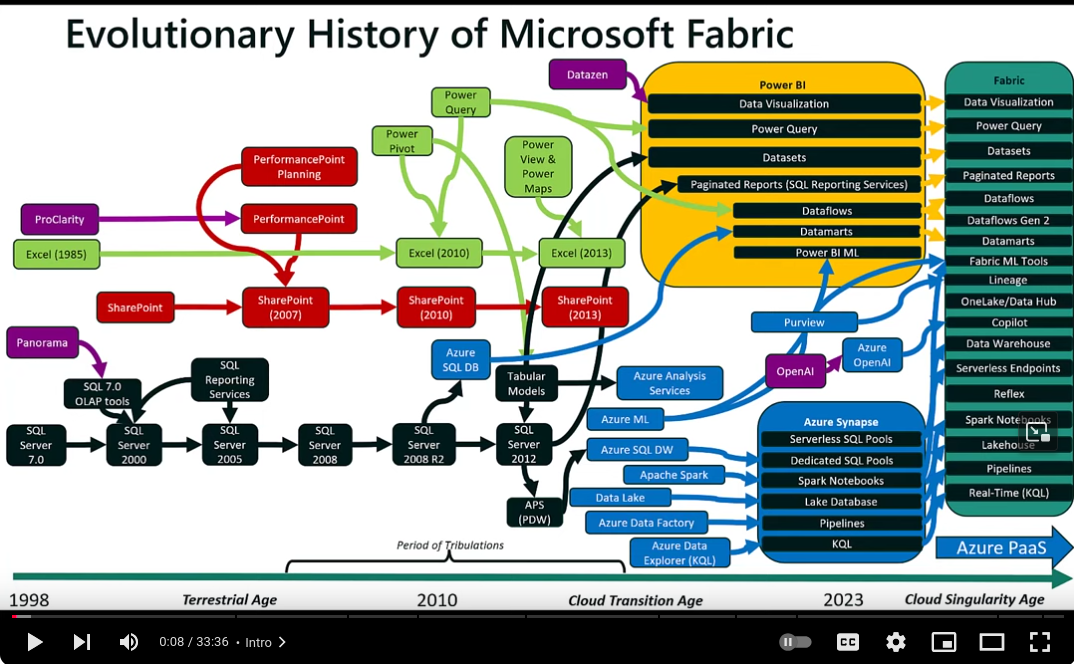
The history of Fabric is just the opposite: it’s a combination of numerous Microsoft products into a platform by one of the largest companies in the world. Evolutionary history of Fabric is well described in the Insights and Outliers channel in YouTube.
Fabric enters a bit late into the data platform race, so this is Microsoft’s do or die moment in data. How does the platform compare to Databricks? In the next part of this series, we’ll continue with a feature-level comparison of the platforms.



